DeepSeek's Engram Gives LLMs a Dedicated Memory Lane
Large language models waste enormous computational depth reconstructing facts they already "know." DeepSeek's Engram module fixes this by adding a fast-lookup memory system alongside neural computation, yielding surprising gains not just in knowledge retrieval but in reasoning, coding, and math. The paper "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models," published January 12, 2026 by researchers at DeepSeek-AI and Peking University, introduces a fundamentally new architectural primitive called Engram. The module modernizes classic N-gram embeddings into a constant-time O(1) lookup system that complements the now-standard Mixture-of-Experts (MoE) approach. When scaled to 27 billion parameters under strictly matched compute budgets, Engram outperforms pure MoE baselines across nearly every benchmark tested, with the largest improvements appearing in general reasoning (BBH +5.0, ARC-Challenge +3.7) rather than the knowledge-retrieval tasks where a memory module would intuitively help most.
Key Takeaways
- DeepSeek's Engram adds a fast-lookup memory table alongside transformer computation, treating knowledge retrieval and reasoning as separate sparsity axes.
- Optimal performance follows a U-shaped scaling law at roughly 75-80% compute and 20-25% memory allocation per parameter budget.
- Engram-27B outperforms the equivalent MoE-27B baseline by +5.0 on BBH, +3.7 on ARC-Challenge, +3.0 on HumanEval, and +2.4 on MATH, despite sharing the same activated parameters per token.
- Memory improvements unexpectedly propagate to reasoning, coding, and math tasks because freeing neural depth from factual lookup gives the model more effective layers for complex computation.
The paper at a glance
The full title is "Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models." The 14 authors are Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, and Wenfeng Liang, spanning Peking University and DeepSeek-AI. DeepSeek's founder Liang Wenfeng is a co-author, signaling the company views this as a core architectural direction. The code is open-sourced at GitHub under Apache 2.0 license, and the paper has been widely discussed as a likely foundational component of the anticipated DeepSeek-V4 model.
Why current LLMs are wasting compute on trivial lookups
The central insight motivating the paper is that language modeling involves two fundamentally different workloads that current architectures handle identically. The first is compositional reasoning, combining concepts, following logical chains, understanding context, which genuinely requires deep neural computation. The second is knowledge retrieval, recognizing that "Alexander the Great" is a historical figure, that "New York City" is a place, or that "By the way" is a discourse marker. These static, local patterns are formulaic and predictable, yet Transformers must reconstruct them from scratch every time using multiple layers of attention and feed-forward computation.
The paper illustrates this waste with a striking example from prior interpretability research. When an LLM encounters the phrase "Diana, Princess of Wales," it takes six full transformer layers to resolve the entity. Layer 1-2 identifies "Wales" as a country. Layer 3 broadens to Europe. Layer 4-5 recognizes "Princess of Wales" as a title. Only by layer 6 does the model arrive at the specific historical person. This entire multi-layer reconstruction process is essentially the model rebuilding a lookup table through expensive computation, the neural equivalent of calculating someone's phone number from first principles instead of checking an address book.
The researchers argue this is architecturally avoidable. Classical N-gram models, a technique dating back to Claude Shannon in the 1950s, captured exactly these local, static patterns with cheap table lookups. The question is whether this primitive can be meaningfully integrated into modern transformer architectures.
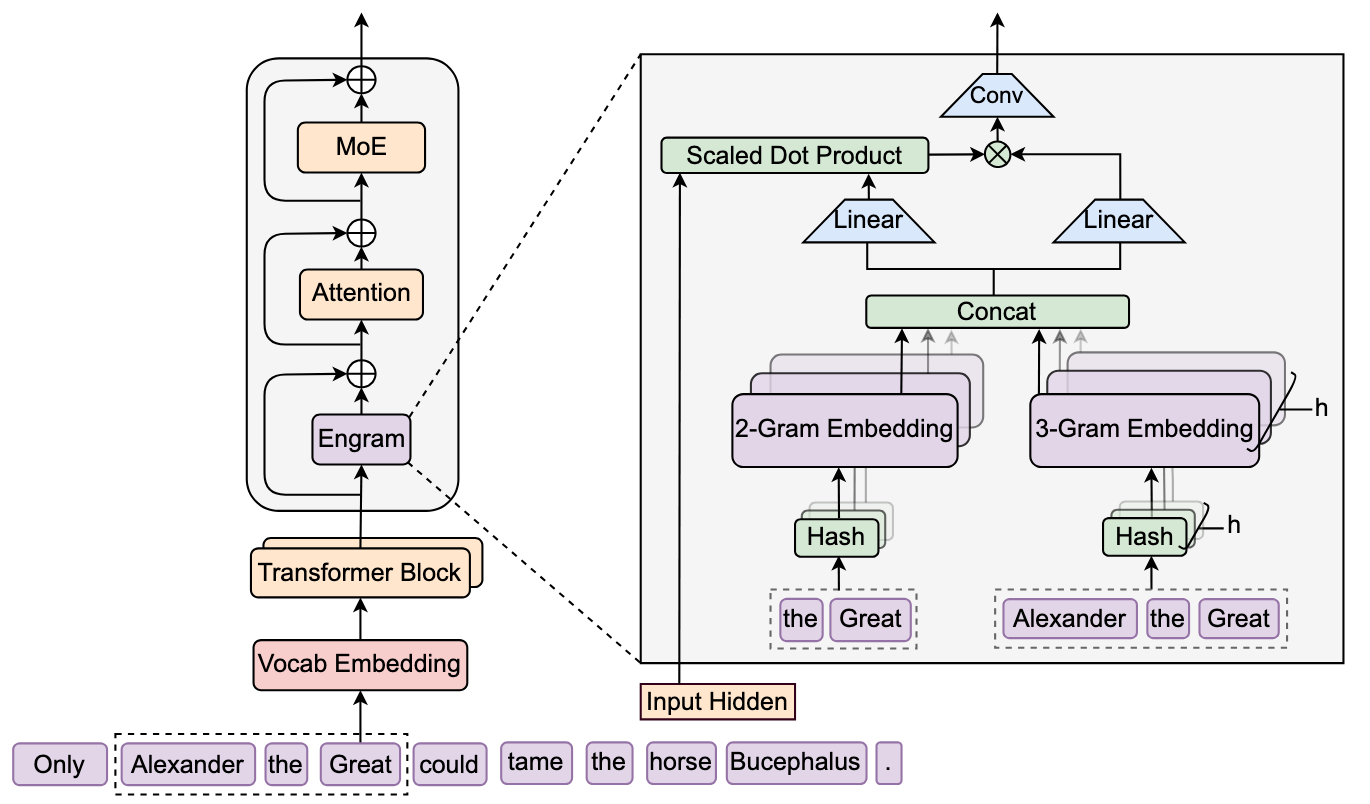
How does DeepSeek's Engram memory system work?
Engram operates in two phases: retrieval and fusion. During retrieval, the module extracts suffix N-grams (sequences of 2-3 consecutive tokens) from the input, compresses them through a vocabulary normalization step, and uses deterministic hash functions to look up corresponding embedding vectors from a massive table. During fusion, these static embeddings are dynamically modulated by the current hidden state through a context-aware gating mechanism before being injected into the transformer's residual stream.
Tokenizer compression is the first innovation. Standard subword tokenizers assign different IDs to semantically equivalent forms: "Apple" and "apple" and "_apple" all get separate tokens. Engram applies Unicode normalization and lowercasing to collapse these into canonical identifiers, achieving a 23% reduction in effective vocabulary size for a 128K tokenizer. This maximizes the semantic density of the N-gram lookup space.
Multi-head hashing solves the combinatorial explosion problem. Directly storing embeddings for every possible trigram would require trillions of entries. Instead, Engram uses multiple independent hash functions (8 "heads" per N-gram order) that map each compressed N-gram to an index in a prime-sized embedding table. Think of it as having 8 different librarians, each with a different shelving system, all looking up the same query. If one librarian's result is noisy due to a hash collision, the others compensate. The retrieved embeddings from all heads and N-gram orders are concatenated into a single memory vector.
Context-aware gating is perhaps the most critical design choice. The retrieved embeddings are static and don't know the surrounding sentence. The word "bank" in "river bank" and "bank account" would retrieve the same N-gram embedding. To resolve this ambiguity, Engram uses an attention-like mechanism where the current hidden state (which has already seen context through preceding attention layers) acts as a query, and the retrieved memory provides keys and values. A sigmoid gate controls how much of the retrieved information passes through. If the memory contradicts the current context, the gate suppresses it toward zero. This is followed by a lightweight causal convolution to expand the receptive field.
Crucially, Engram is not applied to every layer. The paper finds that inserting it at layers 2 and 15 (in a 30-layer model) achieves optimal results, early enough to relieve the backbone from static pattern reconstruction, but after one round of attention provides enough context for the gating mechanism to work.
What is the optimal balance between memory and computation?
The paper's most theoretically elegant contribution is the Sparsity Allocation framework. Given a fixed total parameter budget, how should spare capacity be divided between MoE experts (conditional computation) and Engram embeddings (conditional memory)? The researchers define an allocation ratio ρ, where ρ=1 means all spare parameters go to MoE experts and ρ=0 means all go to Engram memory.
Experiments at two compute scales (5.7B and 9.9B total parameters) reveal a consistent U-shaped curve: both extremes perform poorly, and the optimum falls at ρ ≈ 75-80%, meaning roughly 20-25% of spare parameters should be allocated to memory. This finding is stable across both compute regimes, suggesting a robust architectural preference.
The interpretation is intuitive once stated. When the model is MoE-dominated (ρ→100%), it lacks dedicated memory for static patterns and wastes computational depth reconstructing them. When it is Engram-dominated (ρ→0%), it loses the dynamic reasoning capacity that MoE provides. Memory cannot replace computation for tasks requiring contextual inference. The sweet spot uses computation for what requires computation and lookup for what requires lookup.
In a separate "infinite memory regime" experiment, the researchers fix the MoE backbone and progressively scale the Engram table from 258K to 10M slots. The result follows a strict log-linear power law: larger memory consistently improves performance without requiring additional compute, establishing Engram as a predictable, independent scaling knob.
How does Engram perform on benchmarks?
The paper trains four models for comparison: Dense-4B (baseline), MoE-27B (26.7B parameters, standard MoE), Engram-27B (26.7B parameters, same total size but with 5.7B reallocated from MoE experts to Engram), and Engram-40B (39.5B parameters, with an 18.5B Engram table). All share identical activated parameters (3.8B per token) and training data (262B tokens).
The results across 27 benchmarks are striking. Engram-27B consistently beats the iso-parameter, iso-FLOPs MoE-27B baseline. The expected wins appear in knowledge-intensive tasks: MMLU +3.4, CMMLU +4.0, TriviaQA +1.9. But the larger, more surprising gains emerge in domains where a static memory module has no obvious benefit. General reasoning sees BBH +5.0 and ARC-Challenge +3.7. Code and math benchmarks improve by HumanEval +3.0, MATH +2.4, and GSM8K +2.2. Even reading comprehension improves: DROP +3.3, RACE-High +2.8.
Long-context performance is perhaps most dramatic. After context extension training to 32K tokens, Engram-27B achieves 97.0% on Multi-Query Needle-in-a-Haystack (vs. 84.2% for MoE-27B) and 89.0% on Variable Tracking (vs. 77.0%). Even an early-stopped Engram checkpoint using only 82% of the baseline's pre-training compute matches or exceeds the fully trained MoE model on most long-context tasks.
Why memory helps reasoning: the effective depth hypothesis
The paper's mechanistic analysis explains the counterintuitive reasoning gains through two interpretability tools. LogitLens projects each intermediate layer's hidden state through the final prediction head, measuring how close each layer is to the model's final answer. Engram models show dramatically lower divergence in early layers, meaning they reach "prediction-ready" states much faster, indicating the backbone spends less time on basic feature composition.
Centered Kernel Alignment (CKA) compares the representational geometry across layers of different models. The key finding is a distinct upward shift from the diagonal: representations at layer 5 of Engram-27B align most closely with representations at approximately layer 12 of the MoE baseline. In other words, Engram's shallow layers are functionally equivalent to much deeper layers in the standard model.
The interpretation is elegant: by providing precomputed static knowledge through lookup, Engram effectively "deepens" the network without adding layers. The early layers no longer need to spend their capacity reconstructing named entities and formulaic patterns. This frees them, and the attention mechanism, for higher-level compositional reasoning and long-range dependency tracking. It is this freed capacity, not the memory itself, that drives the reasoning and coding improvements.
A sensitivity analysis confirms this functional division. When Engram is ablated (turned off at inference time), factual knowledge tasks collapse catastrophically, with TriviaQA retaining only 29% of performance. But reading comprehension tasks are remarkably resilient, retaining 81-93%, confirming they rely primarily on the backbone's attention mechanism rather than stored memory.
Infrastructure-aware design makes 100B-parameter tables practical
The final major contribution is a system co-design that makes massive memory tables feasible. Unlike MoE routing, which depends on runtime hidden states and cannot be predicted before computation begins, Engram's hash lookups are entirely determined by the input token sequence. This enables a prefetch-and-overlap strategy: while the GPU computes layer N, the system asynchronously retrieves Engram embeddings for layer N+K from host CPU memory over PCIe.
The paper demonstrates this with a 100-billion-parameter Engram table entirely offloaded to host DRAM, tested on NVIDIA H800 hardware. The throughput penalty is less than 3% (e.g., 8,858 vs. 9,031 tokens/second for a 4B backbone). The natural Zipfian distribution of N-grams, where a small fraction of patterns accounts for most accesses, further enables a multi-level cache hierarchy, with hot embeddings in GPU HBM and the long tail in DRAM or even NVMe SSD.
This decoupling of storage from compute is strategically significant. It means Engram can scale with cheap system RAM rather than expensive GPU memory, potentially bypassing the "memory wall" that constrains most LLM scaling approaches. A server with 1TB of commodity DRAM could host an enormous Engram table at a fraction of the cost of equivalent GPU HBM.
Where Engram sits in the research landscape
Engram arrives amid an active 2025-2026 resurgence of interest in scaling via embeddings rather than computation. OverEncoding (Huang et al., ICML 2025) scales N-gram embeddings at the input layer via simple averaging, but the paper shows it yields weaker gains per parameter than Engram's deeper integration with context-aware gating. SCONE (Yu et al., 2025, from Google) uses a separate "f-gram" model to contextualize embeddings, but requires additional training FLOPs that make iso-compute comparison impossible. UltraMem (Huang et al., 2025) aims to replace MoE experts entirely with memory layers, while Engram treats memory as a complement to MoE, and the U-shaped scaling law provides principled evidence for why both are needed.
The paper's framing is deliberately ambitious: it positions conditional memory not as an optimization trick but as "an indispensable modeling primitive for next-generation sparse models", a fundamental building block alongside attention and MoE. Community reception has been enthusiastic, with multiple technical blogs calling it a potential "paradigm shift" and several analysts linking it to the anticipated architecture of DeepSeek-V4. The paper has not yet been peer-reviewed, but its origin from DeepSeek-AI, whose published papers have consistently foreshadowed their next-generation production models, lends it substantial credibility.
Conclusion
The Engram paper's most lasting contribution may be reframing what "sparsity" means for LLMs. For years, the field has equated sparse scaling with Mixture-of-Experts, selectively activating computation. Engram demonstrates that selectively retrieving stored knowledge is an equally valid and complementary axis, one that follows its own scaling laws and yields benefits far beyond the knowledge-retrieval tasks where memory is intuitively helpful. The finding that a static lookup table can improve mathematical reasoning by 2.4 points and coding by 3.0 points, because it frees up neural depth for actual thinking, challenges the assumption that more computation is always the answer. If validated at frontier scale, the conditional memory paradigm could reshape how we design, train, and deploy the next generation of language models.
Written by